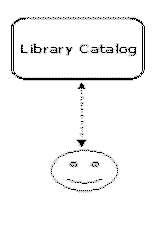
This is a diagram of where we started and this was our situation when the MARC record was first being used. The library of those days had walls and the catalog was a closed box. Note that the user is generally a happy user.
Other complaints seem to be about what we do with the records. One person felt that the last name of a personal name needs its own subfield. Another was unhappy with the collection of items that could be found in a single notes field.
Based on these statements, I can't tell if our problem is with the container or its contents. Nor if it is with the record or our systems. In fact, I can't get a clear picture of the perceived problem at all.
Like a classic disfunctional family, I feel that we are talking around the problem rather than about the problem, and for the next few minutes I'd like to do some therapy on our issues and see if we can't find some underlying problems that give rise to our unhappiness.
So is this a big problem? No, it isn't; and it isn't because we have an enormous advantage over most other institutions, and that is because we have a very large body of highly codified, standards-based data. In other words, we have excellent, well-coded content, and that content can therefore be rendered in any number of record formats through the use of a translation program. I know this because I have worked with many sets of bibliographic data that are not produced in the MARC format. I can tell you that we spend about five percent of our time understanding the record format and translating it to our structure, and the other ninety-five percent of our effort is spent on the content -- content that was not created using cataloging rules, that had changed greatly over time, and that followed no perceivable standards.
If your content is good, if it is consistent, you have what you need to feed different record formats or different systems. If your content is not based on standards and if your coding of the content is irregular, no record format can save you. Content is everything in this business, and we have it.
This quality of being sharable is absolutely essential to our way of life today. Libraries could not return to doing their own cataloging for each regularly published item they receive. The use of shared cataloging has freed us to put our efforts into other services and into non-traditional types of information.
Anything we do to the MARC record to make it less sharable endangers the whole ecology of today's libraries and we should protect it from changes that effect its sharability. Let me give two examples:
Library system developers have recognized that the URL needs to be highly flexible and they have developed system services that don't rely on a URL inside the MARC record. I refer to the SFX technology, Jake, and the work we have done at the University of California. Separating the URL from the bibliographic record is a much better solution to the problem.
We must not underestimate the importance for libraries of sharing bibliographic information. And we have to protect this quality of the MARC record, in part by recognizing that it is a container for bibliographic description and it should remain so.
The primary example of this is the development of the Community Information format. This is really a testament to the creativity of librarians. Having a system that could accept only MARC bibliographic records, they figured out a way to enter information about community resources into those records and create searchable community information files. It was a kluge, a clever kluge. What is astonishing to me today is that we took that kluge and made it a standard. Had this need come up for the first time today we would probably expect libraries to create searchable web-based databases.
Unfortunately, the success of the Community Information format may have led us to believe that all of our data processing needs should be resolved using the MARC record. The Classification format is an example of data that probably should have used a different data structure but we seem unable to consider anything other than MARC. This isn't the fault of the record format, it is our own failing.
I have some slides that illustrate the kind of evolution that we have undergone so far, and where I think we need to go. You will see that the MARC format does not hinder this development because its niche of providing sharable bibliographic data for regularly published works is intact.
#1
This is a diagram of where we started and this was our situation when the MARC record was first being used. The library of those days had walls and the catalog was a closed box. Note that the user is generally a happy user.
#2

In the early days of using the Web, we added links to networked resources from the online catalog. The problem is that the World Wide Web grew enormously and it quickly became impossible to try to filter the world of the web through the narrow gates of the catalog. Besides, our users are onto us: they know where the web is and that they don't have to go through the library catalog to find it. This model is quickly crumbling.
#3
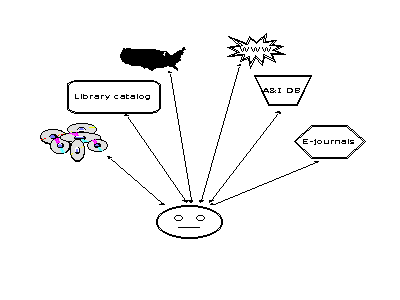
In recognition that there is information outside of the library catalog, some of us have moved to this model, presenting our users with a host of different information resources. But note that my user here is less happy than in previous models. This model is complex and leaves the user confused and overwhelmed. It isn't easy to make sense of data in different formats, from different sources, etc.
In this model the library catalog has become just one of many finding aids for information. It can still be fed efficiently with national MARC record output. It is unlikely, however, that resources from other communities, including the GIS (geographical information system) community, vendor abstracting and indexing databases, social sciences data, image resources, will use the MARC record format. Each type of data has its own data processing needs. This doesn't mean that we can't search or display these data resources in a single system, however, and the next slide shows my "vision" for what the future system might look like.
#4
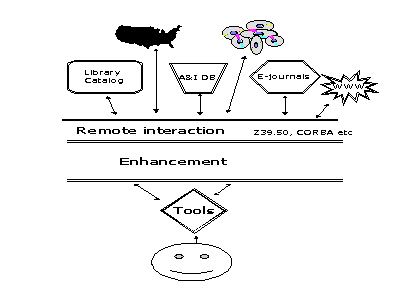
This diagram shows that we can think of all of these resources as a single complex system. The interesting action takes place in the layer called "enhancement". This is where a miracle occurs, and I call it a miracle because we don't yet know how to do this well. But the goal of this layer is to broadcast a search to a variety of information resources and gather the results into a form that will help the user make sense of the heterogeneous retrieved set. This can be done by creating sets of similar items, it could employ relevance ranking, or it could allow the user to select some items and find "like" items within the set.
But I'll go even further than this and say that I think we also need to rethink the user interface. It isn't much help to our users for us to throw a lot of data onto the screen and stop there. Users need tools for dealing with information. They need to store items for future reference, they need to know what they have already seen and what is new to them, they need to compare past results with current results. The beginnings of this toolbox might be in our current personal bibliographic systems, but our goal should be something on the order of Vannevar Bush's famous "Memex" machine -- the personal information space with the ability to link and describe and annotate. Only in our vision, the Memex is not the size of a desk, it probably fits neatly in the palm of your hand.

Copyright Karen Coyle 2000
 Back to
Karen Coyle's Home Page
Back to
Karen Coyle's Home Page