
A common definition for metadata is: "data about data." Although this is a catchy phrase, it doesn't really help us understand what metadata is and why we would use it. So I have a different definition, much less catchy but hopefully more useful.
Metadata is...
Many of us, especially those of us in the library field, think of metadata solely as the data that describes documents, like the library catalog. In fact, there are many other kinds of metadata. For example, here's a good example of metadata:
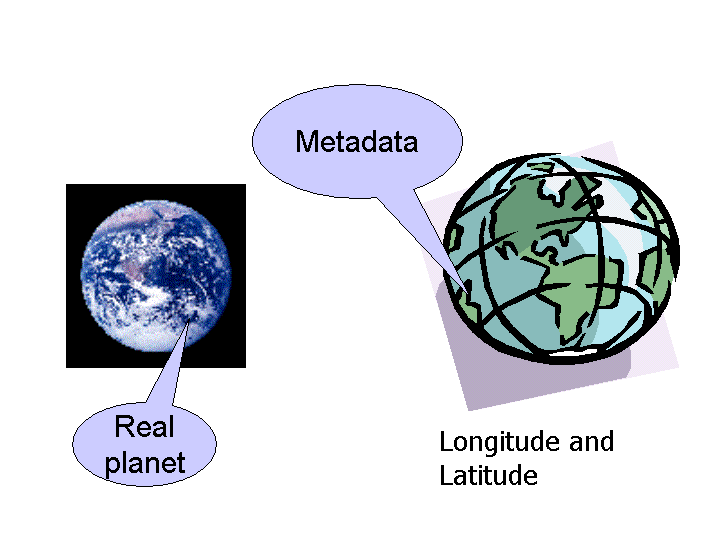
Longitude and latitude are metadata about the planet. They are artificial -- after all, the planet does not have lines going around it. But this metadata was necessary to allow us to communicate about places on a sphere, and it was principally designed by those who needed to navigate the oceans, which are notably lacking in visible features. Note that metadata can often act as a surrogate for the real thing, in this case the planet.
The sciences often make use of metadata because they deal with complex objects that aren't easy to see or work with on their own. For example, here is some metadata from the human genome project:
Most of us don't understand that metadata, but here's some metadata that is more familiar -- a subway map:

If you hold a map of this type up to a street map of the same city, you'll find that the subway map often is not accurate in terms of scale and distances. But that's not its purpose. Its purpose is to help you navigate a complex subway system, to make your transfers at the right places, and to get to your destination. This map is designed for that purpose.
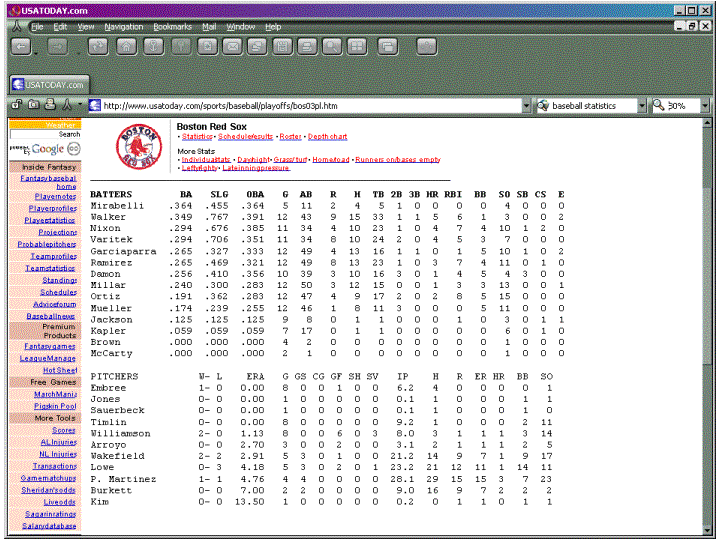
And here's some timely metadata -- this season's Boston Red Sox statistics. This is definitely an artificial representation of the sport, but it captures key information about the season in a form that can be used to compare it to other teams or other seasons:
The metadata that most of us work with relates to information resources, and mainly documents and other similar objects (like maps, musical recordings, etc.). If there is a sine qua non of document metadata, it is the library cataloging record. But there are other forms of document metadata in use today, and I'll give a few examples here.
The first example of non-cataloging metadata is Dublin Core. Dublin Core grew out of a meeting in 1995 in Dublin, OHIO, home of OCLC, which has been the key sponsor of the DC initiative. Dublin Core's purpose is to provide a very simple set of metadata so that people can describe Web-based information resources quickly and easily, even people with no formal training in that activity. It has fifteen core elements (thus the name Dublin "Core"). These simple elements can be further defined to create more detailed metadata, but the core elements have found wide use on the Web and elsewhere, as we'll see further on.
| Dublin Core Elements | |
|---|---|
title creator subject description publisher contributor date type |
format identifier source language relation coverage rights |
You can see that these elements are quite simple. It is easy to create a Dublin Core record for any kind of information resource. Here's this talk represented in Dublin Core:
creator = Karen Coyle
title = Metadata; Data with a Purpose
date = November 14, 2004
format = overhead transparencies
language = English
rights = Karen Coyle, 2004
All of the fields in Dublin Core are optional, and all are repeatable. This may seem a bit too loose, but it has some advantages. For example, let's say that you are about to digitize a large box of photographs that you have in your library's archive, maybe as many as one thousand photographs. You have never created catalog records for them, but you would like to provide some information about each photograph. It's unlikely that you would be able to do full cataloging for that many items, and in fact you may not have very much information about them. With Dublin Core, you could create a very minimal record for each photograph with just a date, a description, and a format, such as:
description = Street scene, with horse buggies, electric trolley car, automobiles and approaching train. Shattuck Avenue, Berkeley.
date = c. 1920
format = JPEG
type = photographic image
There are some disadvantages to Dublin Core, also. There are no cataloging rules that determine how data will be entered in the fields. So although I wrote "creator = Karen Coyle", I could also have written "creator = Coyle, Karen." This allows people who are adopting Dublin Core to make use of whatever rules are common in their community, but it does mean that there is no consistency across different uses of Dublin Core.
Dublin Core may be too simple for some uses, but the MARC21 format is considered by many to be quite complex. It also isn't known outside of the library community. The Library of Congress decided that there was a need for a record that had more fields and was more similar to MARC21 than Dublin Core, but that would seem friendly to non-librarians. For this purpose they developed the Metadata Object Description Standard, or MODS. MODS can carry much of the more common fields from a MARC record, such as author and title, subject headings, and added entries. It doesn't have a place for the full complement of MARC fixed fields (like the 007 codes for physical description) and some of the less used specific notes fields. In addition, MODS is coded in XML rather than the traditional MARC record format and uses mnemonic terms instead of the MARC numeric tags. Here is a MODS field for an author:
<name type="personal">
<namePart>Alterman, Eric</namePart>
<role>
<roleTerm type="text">creator</roleTerm>
</role>
</name>
And here's one for a title.
<titleInfo>
<title>Sound and fury :</title>
<subTitle>the making of the punditocracy /
</subTitle>
</titleInfo>
These may look more complex than a MARC record, but that is because the XML coding is very bulky and may be unfamiliar to you. In fact what you have here is a personal name, "Alterman, Eric," who is the creator of a work with the title "Sound and fury" and the subtitle "the making of the punditocracy." These are equivalent to a MARC 100 and a MARC 245, respectively.
MODS is being used in a number of digital library projects. It is particularly useful for projects that will have some resources that do have a full cataloging record available in MARC format, and other resources that will be given very brief cataloging, perhaps in Dublin Core. There is software that will convert the MARC records to MODS, and it is relatively easy to convert Dublin Core to MODS. If all of the MARC records were converted to Dublin Core records there would be more loss of information than with the MODS record.
Another use of metadata in the library environment is the OpenURL. The OpenURL is a way to carry some bibliographic information over the Internet, usually between an abstracting and indexing database and a special "resolver" service. A library user that is searching on the A&I database finds an article that she would like to see, and clicks on a link next tot he article. The OpenURL conveys the information about the article to the library's resolver service. The OpenURL looks like this:
http://sfxserver.uni.edu/sfxmenu?issn=1234-5678&date=1998&volume=12&
issue=2&spage=134&author=smith jh&title=review of the literature
but it's easier to read if we break it apart into separate lines:
http://sfxserver.uni.edu/sfxmenu?
issn=1234-5678
&date=1998
&volume=12
&issue=2
&spage=134
&author=smith jh
&title=review of the literature
The resolver service receives the metadata, and searches its own database to determine if the library has access to full text of the article through any of its licenses. If it does, it shows the user a link to the full text. If it doesn't, the service may try to determine if the library, or any of its ILL partners, has the hard copy of the article. The OpenURL and the related resolver services were designed to automate the linking between a citation in a remote database and the actual article. The OpenURL has its own metadata formats for articles and for books and chapters, but it can also carry data in other metadata formats, such as Dublin Core.
Not all metadata used for digital resources is used to describe those resources. Some metadata is needed to actually hold digital resources together, like a virtual binding. A book has many pages, but they are held together with binding and covers. When that book is digitized, it is often the case that each page is a separate digital file. In addition, illustrations or photographs from the book or that accompany the book may be digitized separately.

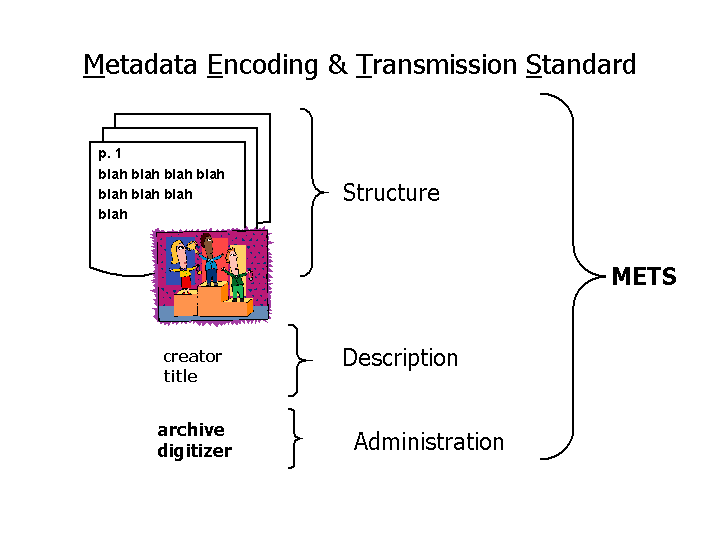
The Metadata Encoding and Transmission Standard (METS) was developed as a way to put a virtual wrapper around digital files that need to be held together. METS not only provides the structure for complex digital documents, it can also bundle the documents together with their descriptive metadata, like Dublin Core, and administrative information about the documents and their digitization.
Libraries are not the only institutions that create metadata for documents and other resources. There are many metadata formats outside of libraries -- what follows is just a small selection.
Publishers have developed a metadata format that allows them to convey product information to online retailers, like Amazon.com or Barnes & Noble. The record, called the ONline Information eXchange (ONIX) has bibliographic information, like authors and titles, ISBNs, but also cover graphics, marketing blurbs, and wholesale and retail prices. ONIX was developed by EDItEUR, and organization that supports electronic data interchange (EDI) standards for publishers.
A very different application, CreativeCommons, is designed to allow creators of web pages and other resources on the web (pictures, music) to embed a copyright statement in their work. The main CreativeCommons metadata is an expression of rights that the creator wishes to grant to anyone who accesses the digital resource. However, CreativeCommons has room for optional descriptive metadata: title of the work, a description, the copyright date and the name of the copyright holder. In the CreativeCommons metadata, these are expressed using the relevant Dublin Core fields, and they look something like this:
<dc:title>Privacy and Free Speech</dc:title>
<dc:date>1998</dc:date>
Similarly the Publishing Requirements for Industry Standard Metadata (PRISM), a metadata standard for the syndication of magazine and newspaper articles, adds Dublin Core fields to its data elements where they are appropriate.
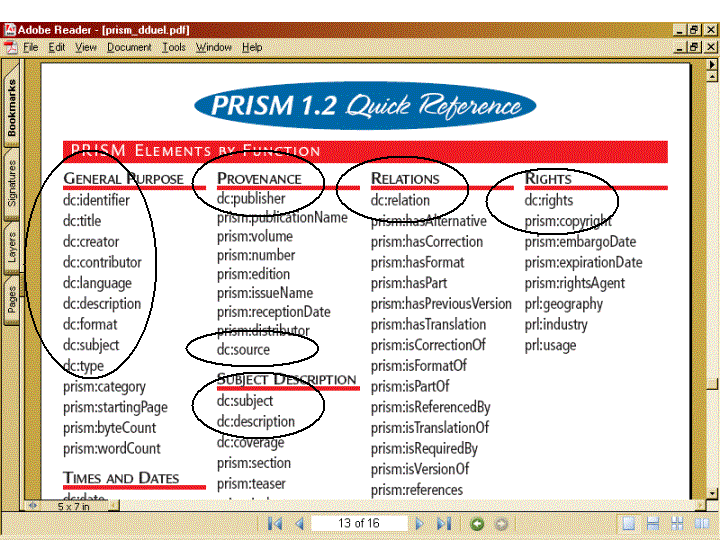
Although there is no application today that combines the Dublin Core data from different metadata standards, in the future the fact that different communities have chosen to use the same metadata for their description of resources may make interaction between them possible.
Does all of this metadata mean that library cataloging is no longer needed? Not at all. Remember that metadata has a purpose, and the purpose of library cataloging is different to that of MODS or METS or Dublin Core, and very different to the purpose of CreativeCommons, ONIX, or PRISM. Just as the library catalog is no longer the only source of information, library metadata is not the only way to describe resources. Libraries will continue to do full cataloging of significant, permanent items in their collections. Non-cataloging metadata may be used in libraries for resources that cannot be given full cataloging, either because they are too numerous or perhaps because they are temporary in nature and do not warrant the effort. With this simpler metadata libraries can provide access to materials that would not normally appear in the library catalog, such as individual slides and photographs, or web sites.
Metadata of a non-library nature is being used by publishers, by web developers, and by others who need to describe digital resources for some reason. Because libraries now interact heavily with providers of information over the Internet, at some point this metadata may interact with libraries and their systems. The OpenURL is an example of metadata that allows different systems to commmunicate information about resources and to automate services that formerly required time and effort on the part of information seekers. There will be more such interactions in our future.